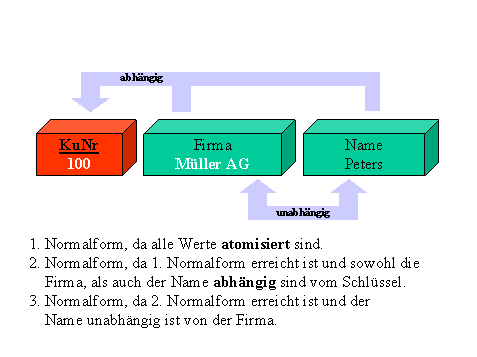
Obwohl es in der Theorie noch höhere Normalformen als die Dritte
Normalform gibt, reicht in der Regel das Erreichen der Dritten
Normalform aus.
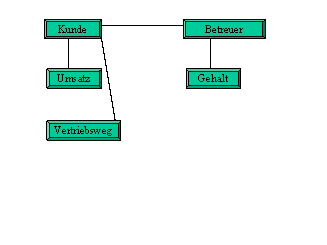
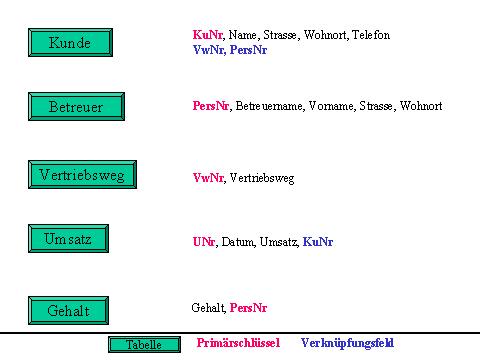
Eine Gesamtübersicht über den derzeitigen, konzeptionellen
Stand unserer Datenbank gibt Abbildung 2-2 und Abbildung
3-2.
Vorsicht: Verändern Sie nach der Konzeptionsphase Ihre Tabellen
nicht mehr! Insbesondere das Hinzufügen von Merkmalen (Datenfeldern),
weil man feststellt, daß unbedingt noch dieses oder jenes Merkmal
aufgenommen werden müßte, ist kritisch! Wenn Sie Veränderungen
durchführen, überprüfen Sie Ihr Konzept nochmals und überprüfen
Sie vor allem die Einhaltung der Regeln der Normalformen. Oftmals stellt
sich nach der Implementierung der Datenbank heraus, daß gegen wichtige
Regeln verstoßen wurde. Dies kann dazu führen, daß Ihr
Datenbankdesign für größere Datenmengen oder den von Ihnen
gewünschten Zweck ungeeignet ist. Eine komplette Neuimplementierung
ist dann oftmals notwendig.
Tabellenerstellung
In der Tabellenentwurfsansicht sollen exemplarisch die Tabelle
2-2: Teiltabelle Kunden und die Tabelle 2-5:
Teiltabelle Umsatz definiert werden.
Teiltabelle Kunden
Nach der Vergabe des Feldnamens KuNr für das erste Feld muß
entschieden werden, welchen Datentyp der Feldname aufweisen soll. Sinnvolle
Alternativen wären die Datentypen Autowert oder Zahl:
Beim Datentyp Autowert werden automatisch für jeden neuen Datensatz
fortlaufende, eindeutige Zahlen vergeben.
Ist das in diesem Falle sinnvoll? Wenn bereits Kundennummern existieren
und sie daher nicht neu vergeben werden sollen, oder wenn sie eine bestimmte
Syntax aufweisen, sollte der Datentyp Autowert nicht benutzt werden. In
unserem Beispiel wollen wir den Datentyp Zahl verwenden.
Die nächste Frage, die beantwortet werden muß, bezieht sich
auf die Feldgröße des Datentyps Zahl: Sie bestimmt u.a. die
Anzahl der (Nachkomma-)Stellen, den damit darstellbaren Wertebereich, sowie
die weiteren Verarbeitungsmöglichkeiten.
Da die Kundennummer keine Nachkommastellen aufweist, sondern mit Ganzzahlen
dargestellt werden kann, beschränkt sich die Auswahl auf die Feldgrößen
Byte, Integer und Long Integer. Wäre sichergestellt, daß es
niemals mehr als 32.767 Kunden geben wird, würde Integer ausreichen,
ansonsten müßte Long Integer gewählt werden. Wir wollen
die Feldgröße Long Integer nehmen.
Als nächstes überlegen wir, ob die Eingabe einer Kundennummer
notwendig ist. Da die Kundennummer einen Kunden eindeutig identifiziert,
sollte auch die Eingabe einer Kundennummer erzwungen werden. Dies erreicht
man, indem die Eigenschaft Eingabe erforderlich auf "Ja"
gesetzt wird (der Standardwert "0" sollte dann gelöscht werden).
Im nächsten Schritt wird die Kundennummer KuNr als Primärschlüsselfeld
definiert.
Der Primärschlüssel ist ein eindeutiges Kennzeichen eines
Datensatzes und die Eindeutigkeit wird vom System überwacht. Ist es
in diesem Falle überhaupt nötig, die Eigenschaft Eingabe erforderlich
auf "Ja" zu setzen?
Strenggenommen nein, denn (laut Vorgabe) weist die Eigenschaft
Standardwert
den Wert "0" auf. Würde also beim erstenmal ein Datensatz ohne Kundennummer
eingegeben, würde sie automatisch "0" lauten! Beim zweitenmal hingegen
käme die Fehlermeldung "Die von Ihnen vorgenommenen Änderungen
an der Tabelle konnten nicht vorgenommen werden, da der Index, Primärschlüssel
oder die Beziehung mehrfach vorkommende Werte enthalten würde".
Wenn hingegen die Eigenschaft
Eingabe erforderlich auf "Ja"
gesetzt wird, würde bei sonst gleichen Bedingungen lediglich eine
andere Fehlermeldung erscheinen: "Feld <Name> kann keinen Null-Wert
enthalten, da die Required-Eigenschaft für dieses Feld den Wert True
hat. Geben Sie in das Feld einen Wert ein".
Als letztes sollte im Feld Beschreibung ein erklärender Text zum
Feldnamen aufgenommen werden. Einerseits dient es der Dokumentation und
andererseits wird der Beschreibungstext beim Einsatz von Formularen als
Feldeingabehilfe in der Statuszeile angezeigt.
Der Feldname Firma bekommt den Datentyp Text zugewiesen. Die
Feldgröße wird mit 50 Zeichen vorgeschlagen und kann auch in
aller Regel übernommen werden. Unnötigen Speicherplatzbedarf
brauchen Sie an dieser Stelle nicht zu befürchten, da die Feldgröße
für den Datentyp Text dynamisch vergeben wird und Sie hier lediglich
die obere Grenze vorgeben. Damit bei der Dateneingabe der Firmenname nicht
ausgelassen werden kann, sollte die Eigenschaft Eingabe erforderlich
auf "Ja" gesetzt werden.
Der Feldname Name bekommt ebenfalls den Datentyp Text zugewiesen,
wobei die Eigenschaft Eingabe erforderlich "Nein" bleiben
kann.
Für den Feldnamen PLZ muß überlegt werden, welcher
Datentyp zugewiesen werden sollte. Die Postleitzahl besteht aus 5 Zahlen,
ohne Nachkommastellen, es läge also nahe, den Datentyp Zahl zu benutzen.
Hierbei sollten jedoch folgende Überlegungen vorgenommen werden: Die
Feldgröße Integer ist zwar fünfstellig, geht aber nur bis
zur Zahl 32.767. Es müßte also die Feldgröße Long
Integer benutzt werden. Aber was würde mit ostdeutschen Postleitzahlen,
die mit einer 0 beginnen, passieren? Diese könnten nicht erfaßt
werden (Vornullen-Unterdrückung). Ist es denn überhaupt nötig,
den Datentyp Zahl zu benutzen? Nötig wäre es, wenn mit den Postleitzahlen
mathematische Berechnungen durchgeführt werden sollen, dies ist jedoch
nicht der Fall.
Der Datentyp Text ist hier besser geeignet. Er löst einerseits
das Problem mit der führenden Null und andererseits könnte man
noch die Staatskürzel integrieren. Die Feldgröße könnte
auf 8 Zeichen begrenzt werden, ist jedoch nicht zwingend nötig. Die
Eingabe sollte nicht erzwungen werden, da es durchaus denkbar wäre,
daß zum Zeitpunkt der Datenerfassung diese Daten noch nicht bekannt
sind und später nachgetragen werden können.
Die Felder Wohnort und Strasse sind ebenfalls vom Datentyp
Text, wobei die Feldgröße 50 Zeichen betragen und die Eigenschaft
Eingabe
erforderlich auf "Nein" gesetzt bleiben sollte.
Das Feld Telefon sollte ebenfalls vom Datentyp Text und nicht
Zahl sein, da Berechnungen nicht nötig sind, führende Nullen
die Regel sind und meistens ein Zeichen zum Trennen von Vorwahl und Rufnummer
benutzt wird. Die Feldgröße könnte auf 20 Zeichen reduziert
werden.
Die Felder Personalnummer PersNr und Vertriebswegnummer VwNr
sind
Fremdschlüssel, mit deren Hilfe die Anbindung an die Tabellen Betreuer
und Kunden vorgenommen werden. Die Datentypen sollten identisch, zumindest
kompatibel, mit den jeweiligen Feldern aus den Teiltabellen sein. Wir wollen
den Datentyp Zahl, Feldgröße Long Integer nehmen.
Die Eigenschaft Eingabe erforderlich sollte auf "Nein"
gesetzt bleiben, da es möglich sein soll, den Betreuer erst später
einzutragen.
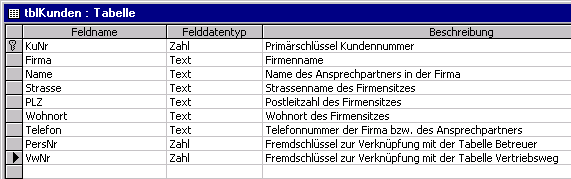
Abbildung 3-1: Tabelle tblKunden
Die Tabelle sollte schließlich unter einem selbsterklärenden
Namen gespeichert werden: Der Tabellenname Kunden bietet sich an, allerdings
hat es sich vielfach eingebürgert, den Objekttyp als Kürzel voranzustellen.
Bei Tabellen also das Kürzel "tbl". Der Tabellenname sollte also "tblKunden"
lauten.
Teiltabelle Umsatz
Zuerst betrachten wir den Grund, warum überhaupt eine eigene Teiltabelle
für den Umsatz genommen werden soll: Würden wir in der Tabelle
Kunden Felder für den Umsatz eintragen oder reservieren, z.B. in der
Form Jan98, Feb98, Mrz98 usw., müßten demzufolge auch jeden
Monat die Eingabemasken auf die geänderten Felder abgestimmt werden.
Außerdem würden wir recht schnell an eine Grenze bezüglich
der Tabellenbreite (also Anzahl der Felder) stoßen. Darüberhinaus
hätten wir enorme Probleme, Berechnungen durchzuführen, wie beispielsweise
den Jahresumsatz eines Kunden.
Daher wird der Umsatz in eine Teiltabelle ausgelagert und so aufgebaut,
daß sich die Tabelle nicht in der Breite vergrößert, sondern
in der Länge (also eine Vergrößerung der Anzahl der Datensätze).
Nach der Vergabe des Feldnamens UNr für das erste Feld muß
entschieden werden, welchen Datentyp der Feldname aufweisen soll. Die Umsatznummer
UNr
ist ein eindeutiger Identifikator (Primärschlüssel) für
jeden Umsatzdatensatz. Er braucht nicht von Hand eingegeben zu werden,
sondern die Vergabe soll automatisch durch ein Autofeld erfolgen. Das Feld
Datum
soll vom Datentyp Datum/Uhrzeit sein, damit später Datumsberechnungen
leichter vorgenommen werden können. Das Feld Umsatz ist vom
Datentyp Währung.
Bei den Feldern Datum,Umsatz und KuNr sollte die
Eingabe erforderlich sein, da sonst die Anlage eines Datensatzes sinnlos
wäre. Außerdem sollte die Eigenschaft Standardwert nicht auf
"0" stehen, damit die erforderliche Eingabe nicht übergangen werden
kann.
Das letzte Feld, die Kundennummer KuNr, ist wieder ein Fremdschlüssel,
mit dessen Hilfe die Anbindung an die Tabelle der Kunden vorgenommen wird.
Der Datentyp sollte wieder identisch, zumindest kompatibel, zu dem Feld
KuNr
in der Tabelle Kunden sein. Wir wollen den Datentyp Zahl, Feldgröße
Long Integer nehmen.
Gespeichert wird die Tabelle unter dem Namen "tblKunden".
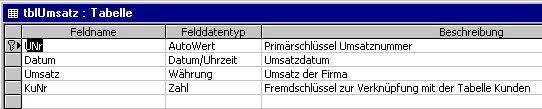
Abbildung 3-2: Tabelle tblUmsatz
Die restlichen Tabellen werden analog erstellt.
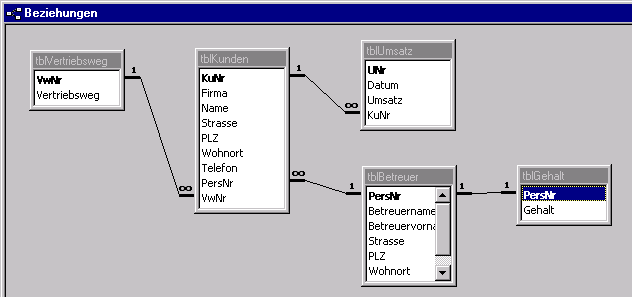
Beziehungen zwischen den Tabellen
Nachdem die Tabellen erzeugt wurden, werden die Beziehungen zwischen
den Tabellen eingerichtet. Im Fenster Beziehungen wird definiert, in welchen
Beziehungen die Tabellen zueinander stehen, und über welche Schlüsselfelder
sie miteinander verknüpft sind.
Dazu müssen wir erst einmal untersuchen, welche Beziehungstypen
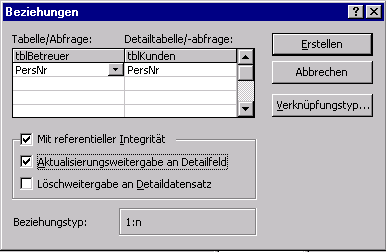
zwischen den Tabellen bestehen. Anhand der Prämissen
können wir dies feststellen: "Jeder Kunde hat nur einen Kundenbetreuer,
ein Kundenbetreuer kann jedoch mehrere Kunden betreuen."
Hier besteht also eine 1:N-Beziehung zwischen Kunde (N) und Kundenbetreuer
(1). Im Beziehungsfenster wird das Schlüsselfeld
PersNr aus
der Tabelle tblKunden auf das Schlüsselfeld PersNr der Tabelle
tblBetreuer gezogen. Die Ziehrichtung ist hierbei unwichtig, da automatisch
die Tabelle zur "1"-Tabelle wird, die den Primärschlüssel besitzt.
Die zweite Prämisse lautete: "Jedem Kunden soll ein Vertriebsweg
zugeordnet werden, mehrere Kunden können demselben Vertriebsweg angehören.".
Hier besteht also eine 1:N-Beziehung zwischen Kunde (N) und Vertriebsweg
(1).
Welche Beziehung besteht zwischen den Tabellen Umsatz und Kunden? Ein
Kunde kann mehrere Datensätze aus der Tabelle Umsatz zugeordnet haben
(z.B. Jan98, Feb98 usw.). Ein Datensatz aus der Tabelle Umsatz kann jedoch
immer nur einem Kunden zugeordnet sein. Auch hier haben wir also
wieder eine 1:N-Beziehung.
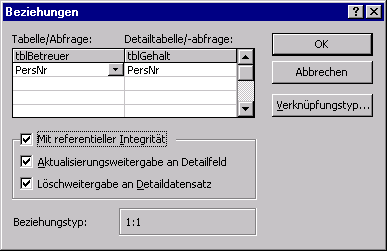
Die 1:N-Beziehung ist die Häufigste, daneben gibt es aber noch
die 1:1-Beziehung. Damit wir eine solche 1:1-Beziehung hier vorstellen
können, haben wir die Tabelle Gehalt aufgenommen: Jedem Betreuer
ist genau ein Gehalt zugeordnet. Strenggenommen hätten wir
die Tabelle Gehalt nicht ausgliedern müssen. 1:1-Beziehungen lassen
sich normalerweise problemlos in die verknüpfte Tabelle integrieren,
es würde nicht gegen die Regeln des Normalisierungprozesses verstoßen.
Gelegentlich macht es trotzdem Sinn, die Tabellen zu trennen, wenn man
beispielsweise unterschiedliche Zugriffsrechte vergeben möchte, oder
eine umfangreiche Tabelle teilen möchte.
Das Ergebnis der Verknüpfungen sehen wir in Abbildung
3.3: Beziehungsfenster mit verknüpften Tabellen.
Systematisches Datenbankdesign